Team: Michael Duarte, Lazaro Clapp
Key Result(s): We explore different strategies for bitrate selection for video streaming and their consequences and pitfalls.
Source(s):
- Te-Yuan Huang, Nikhil Handigol, Brandon Heller, Nick McKeown and Ramesh Johari. “Confused, Timid, and Unstable: Picking a Video Streaming Rate is Hard.” (2012). http://www.stanford.edu/~huangty/imc012-huang.pdf
Contacts: Michael Duarte (mtduarte@stanford.edu), Lazaro Clapp (lazaro@stanford.edu)
Introduction
This report seeks to reproduce, examine and validate some of the results from [1].
The original paper describes some limitations in how popular video streaming services built atop HTTP estimate their available bandwidth in order to select at which video bitrate to stream from server to client. Since bitrate selection has a significant impact on the quality of the video, it is in the streaming service’s best interests to stream video at the highest possible bitrate that would result in uninterrupted playback. However, if the service over-estimates its available bandwidth, it can end up serving video at a slower rate than that at which the client plays it to the user, resulting in interruptions for buffering and a degraded user experience. An optimal service would select the highest bitrate that can be streamed using the available bandwidth and without ever underflowing the player’s buffer.
In the paper, the authors find that the clients for many streaming services consistently underestimate their available bandwidth in the presence of network congestion due to a competing TCP flow. One popular streaming service, referred to as “Service A” in the paper, is used to exemplify the issue.
Figure 4a from the original paper is reproduced to the left below. It shows how, when Service A’s client is left to automatically detect its available bandwidth in the presence of a competing flow, both its network throughput and playback bitrate dramatically degrade. On the other hand, as shown by Figure 5 from the original paper, reproduced to the right below, when the playback bitrate is manually set to a fixed “optimal” value, Service A’s client is able to utilize its fair share of the total network bandwidth.
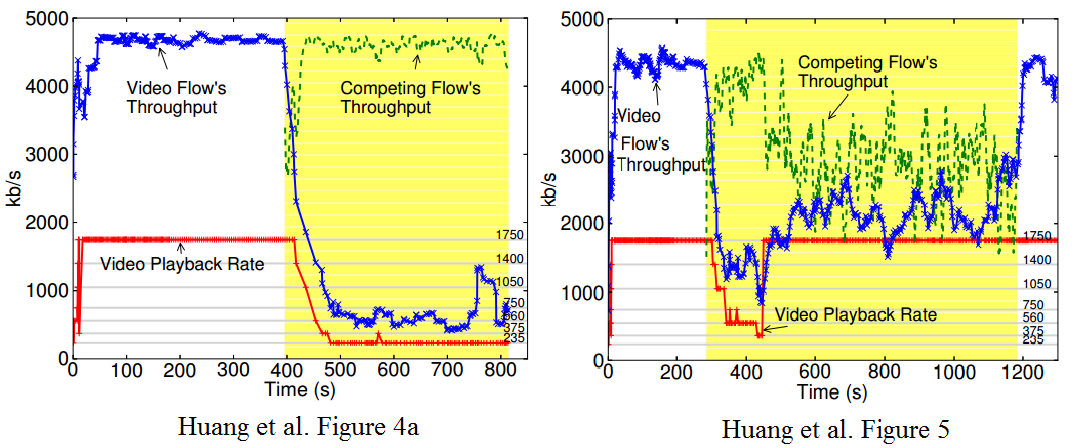
This two results taken together show that the way in which Service A estimates its available bandwidth is what causes the problem.
In this post, we reproduce Figure 4a and 5 from the paper. We do so for the current implementation of Service A’s client and for a simulated version of Service A’s algorithm at the time the paper was written. As we will see, results for this service have changed since the paper was published, hence the need for the simulation. Finally, we test a few alternative algorithms for bitrate selection based on suggestions given in the conclusions of the original paper.
We chose those figures because they show the central problem explored in the original paper. Our experiments are geared towards understanding what makes for a good bitrate selection algorithm. This is a poorly understood problem that has massive commercial implications for content streaming services.
Experimental Setup
Our experiments use the real backend servers of Service A. We do not use Mininet or any other form of network emulation, since we can run our experiments over the real network and the only topology change we need is to create a bandwidth bottleneck at the local host. The tradeoff here is one of realism versus simplicity in the execution of our experiments: interacting with the real Service A backend requires some amount of manual user interaction with Service A’s client (even when running our emulator) for authentication reasons.
We use tcpdump and lsof to monitor network usage and throughput by the different client side programs we use, and wget to generate a competing flow to the same backend server. We use dummynet on Mac OS X to artificially limit our download bandwidth for our experiments in order to better show competition between flows for that resource.
We perform two classes of experiments, those running the current Service A’s webclient and those running our own custom emulator. The emulator has two logical components: a bottom-half that knows how to request a fixed size chunk of audio or video from Service A at a particular bitrate and place it in a playback buffer that drains at a constant rate; and a top-half that handles the logic of issuing requests for specific chunks at the desired bitrate, based on whatever rate selection algorithm we wish to test.
Implementation issues:
We briefly list some of the most interesting implementation issues we ran into while setting up our experiments:
- Each chunk request sent to the server requires an authorization token to be sent with it, these tokens expire and are different for each bitrate. We created a script that allows a user to capture all required tokens by briefly interacting with the real Service A’s client. We set up our emulator and a scripts to read and use this captured tokens (tokens.map)
- Estimating bandwidth usage required us to: map applications to port numbers using lsof, and compute the per-second throughput for every TCP connection by looking at the ethernet header lengths of each TCP packet using tcpdump.
- Detecting the requested bitrate and allowing the emulator to request arbitrary chunks required us to create mapping from bitrates to filenames and from ranges inside the file to chunks. To do this, we had to run a one-time capture of the real Service A client playing a video at every available bitrate.
Results
Real Service A’s client
We first attempted to reproduce Figure 4a using the current version of the real Service A’s client. We set the bandwidth of our system to 1.5Mbps, ran the client alone for 5 minutes and then with a competing wget flow for another 5. We captured and plotted the throughput for both flows and the bitrate selected by the client. This was the result:

We can easily observe that the problem reported in the paper has since been fixed in Service A, as the dramatic drop in throughput no longer occurs when a competing flow is active, and the client achieves its fair share of bandwidth with or without competition (all of it if alone, half if competing with another flow). The selected bitrate is also close to the optimal one in both cases. We have contacted the paper authors and they confirm that this is the case. Unfortunately, we have no information as to the bitrate selection algorithm currently being employed by Service A.
Constant Bitrate Emulator
The first algorithm implemented in our emulator was the simplest one possible: download at a fixed bitrate and always keep downloading as long as the internal playback buffer is not full. The following graphs show this emulator’s throughput and buffer occupancy under a sustainable bitrate (560Kbps with a 1.5Mbps link):


We also show the same graphs for a bitrate that becomes unsustainable as soon as a competing flow is started (1750Kbps with a 1.5Mbps link):


Note that, as would be expected, the buffer underflows under an unsustainable bitrate. In a real streaming client, this would result in playback interruption. The reason the emulator can sustain that bitrate for most of the time it runs alone is that Service A actually seems to use variable-bitrate encodings, which means the bitrate is at most 1750Kbps, rather than strictly 1750Kbps.
Old Service A’s Emulator
Our next bitrate selection algorithm attempted to approximate Service A’s client behavior at the time the original paper was published. Unfortunately, we have no information about how that client operated internally. However, we know it estimated throughput above the HTTP layer and conservatively picked a bitrate based on its perceived available bandwidth. We found that the following algorithm often approximates the results of Figure 4a and makes sense as a possible approximation of Service A client’s old behavior:
- Measure throughput by looking at the Content-Length HTTP header for each downloaded chunk and the time it took to download it.
- Keep a list of the previous three throughput measurements and always pick the minimum as the observed bandwidth.
- Conservatively associate a bandwidth requirement with each available bitrate and pick the highest bitrate for which the current bandwidth is above said requirement.
The following graph shows this algorithm’s behavior on a 5Mbps link:


Note that, once a competing flow is started, our emulator rapidly loses ground to it and ends up requesting video at a bitrate well below its fair share (~325-560kbps when it could easily reach 2350kbps).
The reason for this behavior – explained in the original paper – is that, in the presence of congestion, the TCP flow used to download each chunk takes a while to achieve its full throughput. If the downloaded chunk is small enough, the flow will never achieve a throughput that matches the available bandwidth and our measurement will underestimate the available bandwidth, causing it to download an even smaller chunk next time around. This results in a downward spiral behavior for the emulator’s throughput and bitrate selection.
Buffer-Sense
An observation in the conclusions of the original paper suggested that a buffered streaming client can get away with ignoring the problem of measuring throughput altogether by instead selecting the requested bitrate in a way that tries to keep the buffer occupancy at an intermediate value. That is, we do not care for keeping the buffer full, we just want to prevent it from being empty. In fact, if the buffer is full often, that is a sign that we are downloading at a much lower bitrate than we could.
In our first attempt to make use of this observation, we used an algorithm that selects the bitrate in the following way, based on buffer occupancy:
- If occupancy ever falls below 10% enter a panic mode and download at the lowest available bitrate.
- If occupancy is between 10% and 35%, reduce the bitrate to the next lower value for the next chunk requested.
- If occupancy is between 65% and 90%, increment the bitrate to the next higher value for the next chunk requested.
- If occupancy ever goes above 90%, set the bitrate to the highest available.
The idea was to keep the buffer utilization near the middle of the range, streaming at whatever rates achieved this goal. We tried multiple thresholds for the three cases above, but in all cases we ended up with results similar to the graphs below:


As we can see, the algorithm does keep the buffer at near-half utilization, but causes the bitrate to oscillate wildly, which would make for a sub-optimal video playback experience, as half the time the video quality would be much lower than it needs to be.
Rate-of-Change based Buffer-Sense
Our final experiment was inspired by our results for the previous algorithm. In an attempt to smooth the wildly oscillating behavior of the buffer-sense algorithm above, we designed a bitrate selection algorithm that works based not directly on the buffer occupancy, but on the rate of change of such occupancy:
- Between 10-100% utilization (exclusive), our algorithm looks at the buffer occupancy just after downloading each of the last three chunks. If the occupancy has increased by two chunks during that same period, it changes the current bitrate to the one just above it; conversely, if occupancy has reduced by two, it picks the bitrate just below the current one.
- At <10% utilization, the algorithm hits a panic condition and starts rapidly reducing the bitrate by one for every chunk request.
- At 100% utilization, the algorithm starts rapidly increasing the bitrate by one for every chunk request, ensuring that it reaches the highest bitrate it can sustain.
The reason we require the buffer occupancy to change twice in a very short span of time is that single-step changes are actually not uncommon under the optimal bitrate selection, as the times at which chunks are added and removed from the buffer are not perfectly in sync.
The graphs below show the results for this algorithm (1.5kbps bandwidth limit):


As we can see, this fairly simple algorithm results in near-optimal bitrate selections, with a network usage behavior similar to (and some times better than) that of the current Service A’s client.
Conclusions
Our exploration led us to a better understating of the issues that affect bitrate selection for streaming services in general and in the presence of congestion in particular. Although the results of the original paper do not apply to Service A in its current incarnation, they are not any less valuable: they point out a particular flaw in a seemly intuitive way of performing bitrate selection (as demonstrated by our second algorithm) and the general difficulty of the problem (as demonstrated by our second and third algorithms).
Despite this, our fourth algorithm is extremely simple (the method determining the bitrate at which to download each chunk is barely 33 lines long) and performs really well for our chosen experiment. Of course, evaluation of our algorithm under different conditions is still required.
Reproduce our results!
Get the code:
git clone https://bitbucket.org/lazaro_clapp/cs244-pa3-public.git
Follow the instructions in src/README

Peer review of result reproduction
Alex Trytko and Stephen Young
Hey guys, nice project! Let’s say 4.5 on the reproducibility – we got a couple of graphs that looked a bit different. For example, our buffersize_20 plot.png in buffered_stable in 1500Kbit_s seems to drop down a bit shortly after the competing flow starts, rather than going back up as it seems to in the figure above (unless I’m misunderstanding which graph is which. Perhaps a matching of blog-figure to reproduced-file would ease the comparison a little bit). As we’ve done the same sort of research, however, we understand how plausible it is for results to change depending on current network traffic, etc. Overall, very nice job on the project! Interesting idea to have the emulators request from the real CDNs. Easy to run the experiments and replicate the findings (except for having to replace the instances of ‘en1’ with ‘en0’ =P ). Also, very nice interface for automated token capture =).