Abstract
The Chrome web browser keeps HTTP connections open in the hopes of reusing them and reducing the cost of creating TCP connections, but even then about ⅓ of HTTP requests are with new TCP connections. CDNs complicate things further by changing the server which feeds different parts of a page. The purpose of TCP Fast Open (TFO) is to exchange data during initial TCP handshake to remove an RTT per TCP connection and reduce flow completion time, which makes websites load faster.
Reproducing Results
Our first goal was to replicate table 1 in the TFO paper, which shows page load times, both with and without TFO, for various common web pages. For this we fetched amazon.com, nytimes.com, wsj.com and the TCP Wikipedia pages, with all of their dependencies, and measured the page load time with and without TFO. We tried this with 20ms, 100ms, and 200ms of round-trip time, which we simulated with Mininet along with a custom Chrome shell and Python’s simple HTTP server (serving a locally-cached page), all running on an Amazon EC2 virtual machine with a custom Linux kernel with TFO support. We succeeded in reproducing the results from the paper.
Our results and code can be obtained on our Github TFO repository. They can be reproduced by using our Amazon EC2 AMI: named 474470461255/cs244-13-tcp-fastopen on the US-west-2 Oregon location, AMI ami-c41085f4, launch as c1.xlarge, with security group quicklaunch-1 (to enable SSH), and username “ubuntu”. Once logged on, run sudo run.sh, located under ~/tcp-fastopen/. Make sure the VNC server is on display 1, it should be by default.
Linux Build
We are running Linux kernel 3.7.9, which has built in support for TFO, on our Amazon EC2 instance. After bootup, all we have to do to enable TFO support is to write “3” to /proc/sys/net/ipv4/tcp_fastopen.
We added scripts to enable and disable TFO on demand, which we call from within our run script to show results both with and without TFO.
Chrome Shell Details
The shell we’re using fetches full web pages including all their resources, and fetches them in the order a real user would experience. For this we used a special shell build of Chrome which supports TFO, and which fetches images as well as execute JavaScript (and potentially fetch more based on this execution) as a real web client would, and renders everything to a VNC server’s display.
Scraper
A not-so-obvious use of the Chrome shell is as a scraper: before running anything we feed it a file containing a list of URLs to fetch (e.g. Paper.pages). We then call the Chrome shell in a special page saving mode (with fetch.py) which saves all of the pages fetched under a Paper/ directory, with one sub-directory per host contacted (e.g. Paper/www.amazon.com/), and one file per page retrieved (including path, query and ref parts of the URL). We had to work around filename and path limitations by replacing names that are too long with their base 16 MD5 equivalent.
Client
We then reuse the Chrome shell to simulate fetches, as from a regular client, fully locally with and without TFO. One critical difference with how we run this shell is that it does DNS lookups through a remapping file, so that all queries are routed to a local server instead of going to the Internet. We achieve this by starting one web server per cached host inside the Mininet environment (see Server Details below), and then printing out the 3-tuple of original hostname, local IP address, and local port number. This file is then used by the Chrome shell, whose requests in this mode are only ever fulfilled from localhost.
Data Collection
The Chrome shell also outputs detailed data in both scraper and client mode. Chrome usually records aggregated information that doesn’t leak any private information. Our shell outputs the parts of this information that we found useful. For our experiments we wanted to record more information, we therefore added:
- DNS lookups through time. This is mostly a sanity check, and exposes some of Chrome’s internal object lifetime and frequent DNS queries, which mostly hit the internal cache.
- Pages/resource fetches through time. These are used to validate the effects of TFO, and are used to create load plots.
- Mime type and charset for each page/resource. These are used by the servers to serve pages and resources with the appropriate Mime type: doing otherwise would cause some pages to be downloaded and not parsed by Chrome.
This data is recorded when the shell is in scraper as well as client mode, and can be compared, the former in Paper.fetchlog/, and later in the client/ directory. One caveat in this comparison is that we currently simulate constant latency to each server, but it would be easy to change our Mininet setup to simulate latencies that match the ones collected in scraper mode.
Other Changes
- Between each load we delete Chrome’s cache from the disk to prevent it from serving from cache.
- We changed the shell’s user agent so that it looks like a real client. Some sites otherwise serve a mobile version.
- We added a command-line option to enable TFO for the shell. This ignores /proc/sys/net/ipv4/tcp_fastopen because Mininet’s current virtual environment doesn’t reproduce that of the kernel. A real TFO-enabled Chrome wouldn’t ignore this entry.
- We changed the shell to quit the message loop when it becomes idle (when no requests are in-flight). This is somewhat of an unclean teardown, and sometimes leaks objects.
Rebuilding the Shell
Our Amazon EC2 Linux AMI as well as our repository has a pre-build Chrome shell, which can be recompiled as follows:
- Install the required dependencies from the Linux build instructions.
- Get code from the chromium git repository, and checkout git hash e299150c1203b73d35fb6b1f231af5d740942484.
- Apply the diff provided in our repository.
- make test_shell -j12 BUILDTYPE=Release (or Debug). This takes about 20 minutes to build on a powerful x86 machine.
- strip -s ./out/Release/test_shell (or Debug).
Note that this version of Chrome is somewhat buggy and sometimes crashes. We haven’t narrowed down the issue to our changes or the specific Chrome version, though we’ve tried rebasing our changes at a different hash and experienced worse stability. We obtain results in enough cases that we decided that this issue wasn’t worth fixing.
Server Details
We implemented the HTTP Server using Python’s SimpleHTTPServer request handler, and a class derived from SocketServer.TCPServer that:
- Includes the setsockopt calls to initialize TFO.
- Remaps pages that aren’t found to their base 16 MD5 equivalent filename, as with the Chrome shell above.
- Use Mime type and charset saved by the Chrome shell in scraper mode.
- Saves logs for the servers in the serverlogs/ directory.
Test Rig
Our current test rig is Mininet, which we mainly use to provide IP addresses to each server, and connectivity between the servers and the client. This connectivity has added latencies which we currently hardcode as in the paper, but we could reproduce the latencies measured when the Chrome shell was originally run in scraper mode.
Our initial setup didn’t use Mininet at all: we simply started the Python simple HTTP servers and delayed responses to simulate latency. We started all servers on localhost, and mapped them to different ports.
Issues
There are a few issues with our experiment reproducibility.
The current web pages are different from those that existed when the experiments were conducted. We contacted one of the paper authors and they do not have a cached version of these pages. A possible solution to rectify this is to look at web.archive.org for significant differences between now and the time the paper was written. We ignored this issue because we can see the results of TFO from the pages that we fetched, and they are in the ballpark of the results obtained in the paper.
Some sites use JavaScript to randomly fetch a different page on every load, e.g. ads. We’ve currently ignored this issue, which means that our runs of the client with and without TFO should fail at resolving these pages, but they will be different from our runs in scraper mode. This doesn’t matter much because both client runs with and without TFO equally fail, and therefore measure TFO’s effect correctly.
Results
The results correlate well with those of the original TFO paper, showing reasonably significant latency reductions (in the ballpark of 5-20% depending on the website and RTT). We first generated a table analogous to the first table in the original paper, which shows RTT reduction as a function of TFO being enabled and the RTT setting of the network. This can be seen below:
PageRTT(ms) | PLT (s) |
| no TFO | TFO | Improv.
http://www.wsj.com
100 | 6688.445 | 5807.929 | 13.16%
20 | 4255.73 | 4073.823 | 4.27%
http://www.amazon.com
100 | 3366.808 | 2547.842 | 24.32%
20 | 1450.884 | 1319.65 | 9.04%
http://en.wikipedia.org/wiki/Transmission_Control_Protocol
100 | 4909.855 | 4085.305 | 16.79%
200 | 8403.108 | 7015.135 | 16.51%
20 | 2599.715 | 2301.599 | 11.46%
Additionally, we took the liberty to generate timing diagrams showing the difference between fetching websites with TFO enabled and disabled. These demonstrate the advantages of something like TFO as RTTs increase on the network. An example diagram can be shown below, for fetching the Wall Street Journal website at 100ms RTT. Other plots can be seen in the GitHub repository.
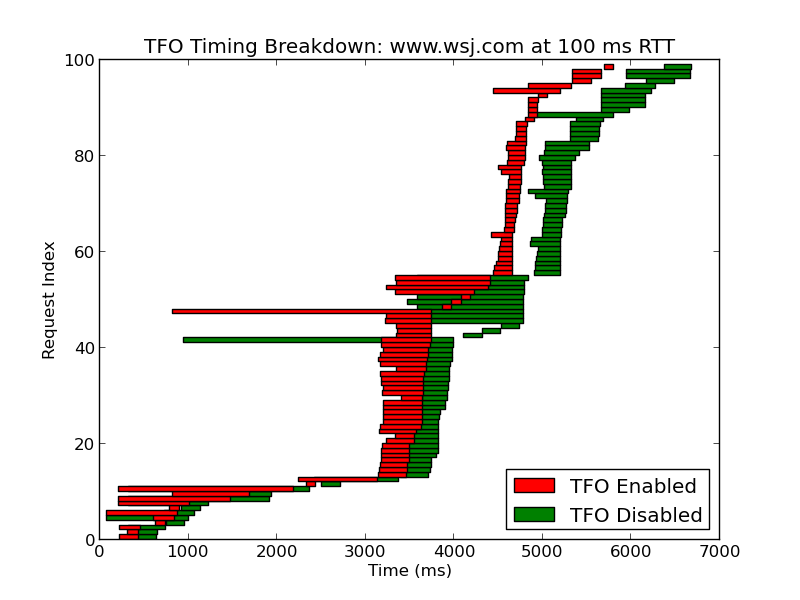
TFO Timing Breakdown: http://www.wsj.com at 100 ms RTT
Exploration
As a further result we’ve experimented with the Alexa Top 100 US websites. This requires significant amount of data, which we haven’t had the time to explore and therefore omitted from our results.
As a further improvement we can collect the CDN layout for these websites from different access points around the world (i.e. run the Chrome shell in scraper mode from different computers), and experiment with different CDN layouts to figure out potential improvements. CDNs require additional TCP handshakes, consolidating them therefore reduces the effect of TFO.
Additional work can be done to evaluate CPU utilization and to replicate Figure 6 in the paper as well.
An optimization that we can investigate would be to measure the benefits of synchronizing the invalidation of cookies between a web site and its associated CDN servers, that is have TFO cookies per domain instead of per IP. By following a common schedule, we could maximize the time in which the entire web site’s resources are also fetched with TFO enabled. The authors of the paper explicitly wanted to avoid such handshakes and synchronization to reduce implementation complexity.
We could also explore allowing Chrome to open more than 6 concurrent connections per domain. This might cause issues with some routers, which can probably be detected and backed-off, but in general could better showcase TFO’s results.

I can’t reproduce this using the AMI. When I spin up the AMI cd into ~/tcp-fastopen and run sudo run.sh, I get a lot of Mininet stuff taking a long time (and consuming a ton of resources; it melted my t1.micro instance, so I’m using a c1.xlarge instance now), then the following error message
Error parsing file: httpwww.wsj.com
Error parsing file: httpwww.nytimes.com
Error parsing file: httpwww.amazon.com
Error parsing file: httpen.wikipedia.orgwikiTransmission_Control_Protocol
[the above group of 4 messages repeated a bunch of times]
Generating basic table (like in TFO paper)
Page RTT(ms) PLT: no TFO (s) PLT: TFO (s) Improv.
httpwww.wsj.com
httpwww.nytimes.com
httpwww.amazon.com
httpen.wikipedia.orgwikiTransmission_Control_Protocol
It seems to have run the experiments quite happily, I didn’t see any errors there, but the measurements aren’t reported. I looked in the output-figures directory as well, but the files in that directory all have mtimes about 24 hours in the past.
So I guess on the 0-5 scale given on Piazza, this is somewhere between a 2 and a 3?
Random note to ease future reproduction: the AMI is ami-c41085f4 and lives in the Oregon (us-west-2) zone (because of EC2 suckage, it’s not visible in other zones)
Looks like there’s a non-deterministic bug in the plot.py script. I will send you a fix there.
Actually, that’s not the case. It looks like you didn’t start the VNC server.
Maybe we weren’t clear about launching the vnc server (I believe the command is vnc4server)
“Our results and code can be obtained on our Github TFO repository. They can be reproduced by using our Amazon EC2 AMI: named 474470461255/cs244-13-tcp-fastopen on the US-west-2 Oregon location, AMI ami-c41085f4, launch as c1.xlarge, with security group quicklaunch-1 (to enable SSH), and username “ubuntu”. Once logged on, run sudo run.sh, located under ~/tcp-fastopen/. Make sure the VNC server is on display 1, it should be by default.”
The authors have told me I needed to start vnc4server in order for Chrome to work. run.sh doesn’t do this and I didn’t gather this from the blog post.
With vnc4server running, run.sh now generates data, although the WSJ and NYTimes web sites have a tendency to crash Chrome, so they don’t always produce results. The results I did get were similar to theirs:
Generating basic table (like in TFO paper)
Page RTT(ms) PLT: no TFO (s) PLT: TFO (s) Improv.
httpwww.wsj.com
20 4247.709 4139.189 2.55478894623
httpwww.nytimes.com
httpwww.amazon.com
100 3327.02 2510.346 24.5467114715
200 35689.013 4363.641 87.7731530429
20 1409.539 1289.114 8.54357346622
httpen.wikipedia.orgwikiTransmission_Control_Protocol
100 4726.305 4465.318 5.52200926517
200 8260.761 6965.573 15.6787976314
20 2557.498 2272.671 11.1369393055
FWIW, there should also be plots, as in:
https://github.com/jfbastien/tcp-fastopen/tree/master/output-figures
Do you mind if I quote a couple of your articles as long as I provide credit and sources back to your website?
My website is in the exact same area of interest as yours and my visitors would genuinely benefit from some
of the information you present here. Please let
me know if this ok with you. Thanks!
Please do!