Eyal Cidon, Sean Choi
Introduction
Ensuring correct and consistent network update procedures is one of the most difficult problems that network operators have to face. Modifications in a network are very difficult to implement correctly, since most updates do not consider the state of the packets in flight. This can cause multitude of problems, ranging from simple packet drops to allowing malicious traffic into the nodes that are supposed to be under the protection.
Recently, the arrival of Software Defined Network (SDN) has eased this process by allowing the control plane to add or remove new nodes. However it is possible for a network to contain thousands of nodes that are interconnected with thousands of links and switches. As the size of the network increases, it becomes nearly impossible for a human being to correctly manage network changes such as inserting, modifying and removing nodes. In “Abstractions for network update“, Reitblatt et. al [1]. introduce the formal definition for a process called Per-Packet Consistent Update. Per-Packet consistent update is a process in which each packet flowing through the network is guaranteed to be affected only by a single network configuration. In other words, the packet is routed through the network either as if the network state is as it was completely before the update occurred, or completely after the update occurred. This makes network updates easier to reason with, as we do not have to worry about the intermittent state of the packet during the update process. The authors also implement a software system called ‘Kinetic’ which takes a new configuration and a network topology, and implements a transition to the new configuration while providing the consistency level Per-Pack or Per-Flow. Given this, the authors show that with some overhead during the updates, the consistency level can be guaranteed throughout the update process.
Goals
These are the list of goals that this paper is attempting to solve.
- Propose general abstractions and the implementation mechanisms for specifying network updates.
- Provide theoretical models that capture the behavior of SDN and prove that the mechanisms correctly implement the abstractions.
- Show that the network updates can be performed consistently without adding huge overheads.
Motivations
The authors start the paper with a quote that states “Nothing endures, but change”. This quote strongly applies to the computer networks. Computer networks are continuously changing, yet there exists no simple solution to perform updates on them easily. In addition to performing the updates, there is no solution to guarantee that the updates are being performed correctly and the state of the network does not shift to an unintended state during the update process. Manually tracking this state is very difficult for a human being, since this requires tracking all possible transitions and states, and in a large, highly complex and highly interactive network this is intractable. Finally, the authors argue that the intermittent state should not be of concern for any network designers and operators. Instead, they should only focus on the end configuration of the network.
Reproduction Goals and Motivation
We decided to reproduce the results in table 2. In this experiment the authors deploy a few network topologies, on each of these topologies they perform a series of events that require reconfiguration, such as dropping hosts and links. They measure how much overhead did Kinetic add to the roleset of each switch compared to the ruleset required for the configuration alone, for instance if both the old and the new configurations required 100 rules on a switch, and Kinetic in order to work keeps both the old and the new rulesets on the switch then we have 100% overhead. The table also shows how many operations the transition between the configurations required.
We decided to reproduce these results because this paper is very much theory based. From our experience while very theoretical paper have the strength of mathematically proving that they solve the question they came to answer, but they tend to do this in ways which are not always practical to implement in real life. In the case of this paper, while it is proven that the update will be consistent, it might do so by requiring many operations, and therefore longer update time. Additionally the overhead measurement is also important because if we were to implement this system on a actual network, we will need switches with adequate compute and memory resources to accommodate this overhead, if the overhead is larger than the authors claim then the system might end up being too costly to implement.
Original and Reproduction Results
The original paper results are shown here:
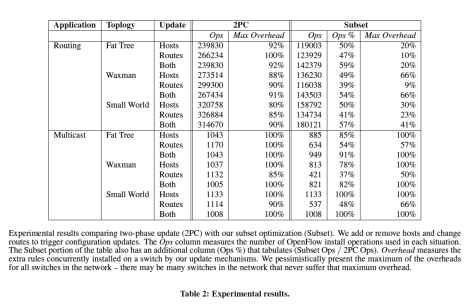
The original results were run using 48 switches and 192 hosts. Around 20% of host, switches or both are removed in each test.
Due to technical difficulties we were only able to reproduce results for 30 switches and 120 host, with that in mind we can see that the results are quite consistent for the 2PC case, but a little bit worse especially for Multicast. Important to note while the number of operation declined because of the size of the network the overhead did not change and in cases was even worse. Our subset results are much worse than those in the original paper. Our different results might be because we use smaller graphs so subsets include more percentage of the switches, and different effects might happen in multicast, or there was some bug in the code. Our results are shown here:

Challenges
During the replication steps we face a few challenges.
- First and the most interesting challenge that we faced is the challenge regarding identifying the correct software project to use for the project. In the paper, the authors discuss that their results were generated using a software called Kinetic that sits on top of a NOX controller [5]. However, after their publication, another project of the same name within the similar domain has also been published by Nick Feamster at Princeton. To worsen the problem, the authors of this paper never seemed to have released their code to the public, or at least it is no longer available. Thus, we initially were under the confusion that the old Kinetic project has evolved into the Kinetic project released by Professor Feamster. This led to obvious issues of huge time waste. Also, we had to reach out to the authors manually to obtain the source code. Luckily for our case, we were able to reach the authors in time, but if future groups fall into the same pitfall, they might not have the luck of reaching the authors to receive their code in time.
- Another challenge arose when setting up the experiment. The code that the authors provided has numerous dependencies that are obsolete and no longer supported. For example, we had to use the Ubuntu 10.04 release, since the repository of the newer kernel releases had a newer version of autoconf, that limited our ability to compile the old version of NOX, which is called NOX-classic. The authors seemed to have used Mininet 1.0 [2,3] to replicate the result (not specified in the paper), but Mininet 1.0 install script failed miserably, as it was referring to many repository locations that no longer exist. Also, the install script seemed to suggest that the default configuration is for a 32-bit system, which is hard to find nowadays. Thus, we had to manually search the internet to find the new locations for these old software, and even if we were able to find it, we had to guess, mostly through trial and error, to find which version (or even which commit) that the authors used.
- Another issue we had replicating the result is the lack of instructions to use the software. Their software was obviously not intended to be released, thus it contained nearly no documentation and nearly no comments. Also, to worsen the situation, the documentation that they had on installing NOX was very outdated and was no longer applicable even on most commits of the NOX-classic repository. Thus, we only had to guess what they would be doing using the new NOX controller and made the configuration changes accordingly. In addition, it was unclear what the parameters are supposed to do for their program, so we had to iteratively guess through the domain of many parameters to gain the correct understanding of the system.
- Finally, the last issue we had is the issue with the unclear description of what they were measuring. The paper mentioned that they were measuring the number of Openflow[4] install rules and the overhead that occurs when performing the consistent updates. However, they did not specify what these install rules are, and given how Openflow may change greatly over time, it was unclear if we can replicate the similar results on the newer version of Openflow.
Critique of Paper
The paper is very mathematical heavy and evaluation light. The abstractions the paper introduces are very useful and the mathematical proofs have a lot of strengths. However, the lack of more evaluation is a detriment to the paper, they only measure the number of operations it takes to perform an update and not how much time. It would be very interesting to see how long does it take to perform an update. Also the configuration changes in the paper is only removing links and switches, it would be interesting to see the results for topology changes such as adding more nodes or changing the network from one logical topology to another. Another weak point in the evaluation is that it is all simulated, a test in an actual network would be interesting.
Extension
As an extension, we decided to add a topology to see if the trends that they show are generally applicable. We ran tests on a Gn,m version of the Erdős-Rényi dense random graph [6]. We believed that in this case a lot of overhead will be created by the system because due to the density of the graph many switches will be affected by every update. Our results, shown below, prove indeed indicate this:

Choice of Platform and Steps to Reproduce
We were able to partially reproduce the results on Amazon EC2. A word of caveat is that the repository and the commit IDs that we have used may out out of date at any random time in the future, thus it may not be reproducible in the near future.
The link to the detailed instructions to replicate the experiment is in https://github.com/yo2seol/cs244/tree/master/pa3/README.md
The entire setup is somewhat reproducible, we were able to reproduce the 2PC results with somewhat accuracy, but was unable to reproduce the subset results. We believe this is either a factor of using smaller networks, which means more percentage of the switches are involved in each subset. Or this is influenced by the issues we faced when running the code.
I think the parameters of the setup that will affect the reproducibility the most is the availability of the code and its legacy dependencies. Most, if not all, dependencies of this projects are not backwards compatible, thus it requires a very old OS and links to the packages that might no longer exist. Also, we were not able to capture the effects of the difference in 32-bit and 64-bit setup on the final results, but it is also a good candidate to suspect if one was unable to reproduce the results.
README
Readme is located in https://github.com/yo2seol/cs244/tree/master/pa3/README.md
Suggestions
If anyone is interested in reproducing results in a newer environment, we suggest trying to port the old codebase to work with the new versions of Mininet and POX. Also, I think it would be great to try to reimplement their consistent update logic in different views and measure the effects on update times, packet latencies or some other metrics rather than the number of operations on OpenFlow. It would also be great to look at setting this up on a distributed set of boxes and on real OpenFlow supported hardware to see if the results hold up.
References
-
Reitblatt, M., Foster, N., Rexford, J., Schlesinger, C., & Walker, D. (2012). Abstractions for network update. Sigcomm, 323–334. http://doi.org/10.1145/2342356.2342427
- Mininet http://mininet.org
-
B. Lantz, B. Heller, and N. McKeown, “A network in a laptop: Rapid prototyping for software-defined networks,” in HotNets, Oct 2010.
-
N. McKeown, T. Anderson, H. Balakrishnan,
G. Parulkar, L. Peterson, J. Rexford, S. Shenker, and J. Turner, “Openflow: Enabling innovation in campus networks,” SIGCOMM CCR, vol. 38,
no. 2, pp. 69–74, 2008. -
N. Gude, T. Koponen, J. Pettit, B. Pfaff, M. Casado,
N. McKeown, and S. Shenker, “NOX: Towards an operating system for networks,” SIGCOMM CCR, vol. 38, no. 3, 2008. - Erdős–Rényi random graph model https://en.wikipedia.org/wiki/Erd%C5%91s%E2%80%93R%C3%A9nyi_model

Reproducibility Rating: 3.5
Reproducing the code was tricky at times. There were 48 tests, each one running for approximately 30 minutes. While we initially hoped that we could just leave the tests running overnight, they all hanged nondeterministically so it wasn’t quite that simple (especially since they were 30 minute tests, so it was hard to know if it hanged or not). We wrote some code to make it easier to restart the system and rerun the tests when it hanged. It also would have been very helpful some sort of script that outputted the results into the format of the blog post.
As for the results, some numbers matched but there were several that didn’t—we got 100% max overhead for all of the Fat Tree subset results (both routing and multicast), while the blog post had numbers in the ~60%. Almost all the results with a max overhead of 90% got 89% in our reproduction, but that seemed acceptable. Given the difficulty of reproduction and the fact that only some of the numbers were off, we decided this fell between a 3 and a 4.
The blog post explained the topic very clearly and the subject was definitely ambitious, especially given that the paper was very theory based. It was also very interesting to see the results of their extension match the prediction that denser graphs result in a lot of overhead.
One thing it would have been nice to hear a bit more of would be if, given their experience, Eyal and Sean believe that this is actually implementable on an actual network (aside from the obvious challenges of outdated software and whatnot). They briefly discuss it in the motivation section, but it would be nice to get their final take on it.
-Keziah and Felipe