Padmapriya Duraisamy (ppriya @ stanford) and Venkata Durga Ganesh Reddy Aakula (durga @ stanford )
Introduction
Data Center TCP (DCTCP) is a congestion control protocol designed specifically for Data Center networks. Data centers host applications which receive flows that require low latency (for short flows), high burst tolerance and high utilization (for long flows). Of all the requirements stated above, the latency directly impacts the quality of service and hence revenue. To provide low latencies, DCTCP uses explicit feedback (ECN) from the congested switches and tries to maintain very low buffer occupancies. This can be achieved at almost no additional cost as the modern switches come with ECN feature. The switches mark a packet as congested if and only if the buffer occupancy exceeds a threshold K, which is a configurable parameter. By adjusting the value of K, one can control the maximum latency a packet can incur. Also DCTCP enabled sender computes the fraction of packets (out of a window worth of packets) that are marked congested (ECN) and adjusts the ‘cwnd’ proportional to the amount of congestion. This way, we don’t compromise on the utilization of the bottleneck link. In the case of conventional TCP, cwnd is reduced by half upon congestion which compromises on the utilization. Thus, TCP reacts to congestion but not to the extent of congestion. Also TCP doesn’t have any mechanism to constrain the buffer occupancy, so controlling the round-trip delay is not possible. In both these aspects, DCTCP performs better than TCP.
The main goals of the paper are two folds – First, identifying the impairments that hurt performance in data center networks by measuring and analyzing production traffic. The second goal is to propose DCTCP scheme and to show that it outperforms TCP in data center networks by performing some benchmark experiments.
In conventional setup, it is in general very difficult to satisfy both low delay and high throughput constraints simultaneously i.e., if one tries to improve the delay by reducing the queue size, then packet drops may occur which alarms the sender to reduce the ‘cwnd’ which reduces the throughput. Increasing the queue size reduces the packet drop rate but causes the delay to go up (bufferbloat problem). The problem here is not notifying the sender about the congestion quickly. In DCTCP, even though the queue size is large enough, the sender will be notified of expected congestion when the buffer occupancy hits a threshold (K). This way one can control the delays, reduce packet drops and notify the sender quickly about the congestion. This is not just creating a balance between the delay and throughput by compromising one of them but a powerful mechanism to make the sender react to the extent of congestion. This is most interesting thing that we found about DCTCP and so we want to reproduce these results and get a practical sense for the problem and the solution.
With carefully designed traffic patterns, the authors examine how well DCTCP performs when compared to TCP in aspects such as fairness, convergence etc. They demonstrate that DCTCP maintains a very low queue occupancy and achieves a high throughput. Secondly, they performed some benchmark tests to show that DCTCP actually alleviates some performance impairments such as buffer pressure, incast (§3.2 of DCTCP paper [1]) when compared to TCP.
Subset Goal & Motivation
We are interested in studying and replicating Fig 12 and 16 from the paper [1].


Fig. 12 compares the queue occupancy over time as measured in the experiment with the theoretically derived equation :
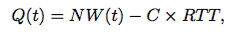
It is obvious from the above equation that similar to TCP, the queue length follows the window and thus exhibits a sawtooth pattern. However, unlike TCP, the sawtooth does not fall to a half of Qmax every time.
Fig. 16 compares the convergence time of DCTCP with that of TCP. Convergence time is defined as the time taken for the flows to grab their fair share of the network. DCTCP trades off low latency and high throughput for higher convergence time. This is because DCTCP uses the ECN markings to gradually alter the congestion window, thus taking few RTTs longer than TCP to converge. However, the authors claim that for the RTTs and short flow traffic patterns typically observed in data centers, the difference between convergence time of TCP and DCTCP is not so significant.
The reason we chose to replicate the above two figures are : Fig.12 presents a very important result from the paper. It compares the theoretical and analytical queue lengths. The theoretical expression for queue occupancy is one of the 2 key contributions of the paper. Fig 16 compares an aspect of DCTCP which is its potential drawback with TCP. Although DCTCP takes longer to converge, it exhibits lesser variability unlike TCP. We want to study whether this is true and see how this varies as N increases. According to the paper, we should see no variation. Another reason we chose these particular figures to replicate is because these haven’t been studied in previous years and we wish to make some original contributions rather than study something that others have already shown to be reproducible.
Subset Results
a. Setup validation figure

We decided to reproduce Fig1 from the paper [1] to see if the DCTCP kernel patch was successful. The authors used actual hardware to validate DCTCP – they measured the queue occupancy on a Broadcom Triumph Switch to which two hosts are connected via 1Gbps links. The two hosts setup long lived TCP flows with common receiver on a bottleneck link of bandwidth 1Gbps. The queue occupancy of the switch is measured for both DCTCP and TCP and Fig1 is produced. The maximum queue size was set to 700KB in this set up.
Since mininet doesn’t perform well when operated at 1Gbps link speeds [2], we decided to use 100Mbps links and the same star topology in mininet to reproduce Fig1. i.e., 2 sender hosts and a common receiver host through a switch. We set RTT to be 500 us (250 us on each link). We set the maximum queue size to be 120 packets (176 KB) for our link speeds and delays. We set up long lived TCP flows (using ‘iperf’) from the sender hosts and continuously monitored the queue on the port to which receiver is connected. The following figure shows our findings about the DCTCP and TCP queue occupancies under the topological scenario mentioned above.
From the figure, we can observe that the queue occupancy is low and almost stayed steadily at K (=20 in this experiment) when DCTCP is used. In case of TCP, we see a sawtooth behaviour which is expected since TCP reacts to congestion when the queue is full and a packet is dropped. This is the reason the queue occupancy is higher and so the delays packets incur are longer. From this figure, we realized that our DCTCP kernel patch was successful and we are ready to perform other experiments involving DCTCP which we present below.
b. Convergence test
The authors ran this experiment too on real hardware using a Triumph switch and 6 hosts connected to 1 Gbps links. One of the hosts acts as a receiver and the others are senders. They had one long lived flow from one sender to the receiver and they started and stopped the other senders sequentially at 30 second intervals. We had a similar star topology in mininet where we created 5 senders and 1 receiver. We started iperf connections from the senders to the receiver and timed the iperf connections to simulate the switching off senders sequentially at 30s intervals. We had a sleep(30) after turning on each host to simulate the sequential starting. We ran this set up for both TCP and DCTCP and our figures are shown below :
DCTCP :

TCP:

As can be seen, our results match the author’s results perfectly.
c. Analytical vs Experimental comparison
The authors came up with analytical equations for the maximum and minimum queue occupancies when DCTCP scheme is used. As shown in the figure below, K is the threshold (a parameter of DCTCP configuration described earlier), Qmax is the maximum queue occupancy, A is the amplitude and Tc is the period of sawtooth oscillations. The following equations relate A and Tc with RTT, C (bandwidth of the bottleneck link), K and N (number of flows). The authors derived the equations for a simplified setting i.e., they assumed that all the N flows are synchronized so that all the flows will have identical sawtooth behaviour, making the analysis simple.


We made the theoretical calculations and generated the following plots.
N = 2

N = 10

N = 40

To verify the above equations, we simulated a star topology with N senders and 1 receiver, 100 Mbps links and RTT of 500us (same as setup validation) and had iperf connections from senders to receivers. We could not get perfectly synchronized flows in experimental setup. For N = 40, mininet threw a buffer out of memory error when trying to ping all hosts to ensure all hosts are up. We got the following from simulation :
N = 2

N = 10

N = 40

We think that the reason why we don’t get the perfect sawtooth from the paper is because of the senders being unsynchronized. There is also an order of magnitude difference in the time scales. We think this could be possibly due to the mininet emulation environment. Mininet uses linux containers and emulates topologies using virtual hosts. This might cause timing issues. As a future work, one could try to use NS2 and see if the figure is reproducible. One thing to note is that the we expect the Queue occupancy to cap at 22, 30 and 60 packets respectively for N =2,10 and 40. From the above figures, one can see that this is almost the case. Again, N=40 could be an anomaly due to mininet artifacts.
Critique of the paper
Overall the paper is well written with clear explanations of the DCTCP scheme, experimental validation of the theoretical analysis and comparison to TCP scheme. The way the authors explained things is impressive since it can be easily understood by a reader with little experience in congestion control area. Almost all of the results that the authors presented seemed to be reproducible easily and are not that difficult to interpret. One reason for this easiness is that whenever needed, the authors clearly presented the topology information and the parameters used in conducting the experiments. This helped us in re-creating the experiments inside an emulation platform such as mininet.
In theoretical analysis, the authors assumed that all the N flows are synchronized to make the analysis simpler. For validating the theoretical results, they created an experimental setup using actual hardware but creating synchronized flows in mininet wasn’t possible, so we had to compromise on those results. When we performed the hand calculations (using equations 8, 9, and 10) with the parameters used by the authors, we realized that the period of oscillation of the sawtooth (Fig.12) didn’t match well with what the authors have plotted. This might be due to the approximations that the authors used in deriving those equations.
Challenges
One big challenge we faced was getting the kernel to build. We repeatedly ran into out of memory issues and eventually found the perfect disk size required for the kernel to build successfully. To ensure groups in later years don’t face these issues and to make it easy to reproduce, we have created an AMI of our instance with the DCTCP patch installed. We also installed all the dependent packages needed for our code to run.
Another issue we faced was regarding Mininet 2.3. The latest version of mininet from github threw an error “RTNETLINK answers: No such file or directory” when we tried running the linux tc command on an interface. We tried to explore fixes for this in mininet but we found that this is an open issue with mininet and the authors had not provided a bug fix. So we chose to downgrade mininet to 2.0.0 which the previous batches had used and which seemed to work as expected.
A last minor challenge was also regarding the mininet environment. In the experiments, the authors had used 1 and 10 Gbps links but we found that mininet does not support 10 Gbps and the results were not very accurate at 1 Gbps. We researched online and found a paper [6] that discusses that mininet does not allow accurate measurements beyond 100 Mbps. So we chose to use 100 Mbps.
We did not face any conceptual challenges. The paper details all the parameters used and the concepts and math are nicely detailed in the paper. We had to recalculate the parameters however for the 100 Mbps environment. The part that took the most time to get working was the initial setup portion. Once we had the kernel built and resolved the above issues to get the setup validation figure, it was easier to develop the code and generate the remaining figures.
We noticed some variation in our results due to what we think is load on AWS servers. To solve this issue, we waited for the experiment to stabilize before plotting the graphs by having a sleep statement after starting iperf on the senders.
Platform:
We chose to use mininet although the original paper used NS2 because it is a platform we are familiar with from bufferbloat and CS144. Moreover, previous batches [3,4,5] had used mininet too and [2] shows DCTCP as an example for reproducibility of network research in Mininet. We believe the setup is very reproducible. The parameters of the setup that could affect the reproducibility the most are queue size and link speeds and delays. If the queue size is too large, in TCP you start seeing a bufferbloat like behavior. Link speeds and delays affect the fidelity of the results and if the speeds are too large, artifacts begin to appear in the results. Load on AWS servers could also affect reproduciility.
References
- Mohammad Alizadeh, Albert Greenberg, David A. Maltz, Jitendra Padhye, Parveen Patel, Balaji Prabhakar, Sudipta Sengupta, and Murari Sridharan. 2010. Data center TCP (DCTCP). SIGCOMM Comput. Commun. Rev. 40, 4 (August 2010), 63-7
- Handigol, Nikhil, Brandon Heller, Vimalkumar Jeyakumar, Bob Lantz, and Nick McKeown. “Reproducible network experiments using container-based emulation.” In Proceedings of the 8th international conference on Emerging networking experiments and technologies, pp. 253-264. ACM, 2012.
- DCTCP Mininet test – https://github.com/mininet/mininet-tests/tree/master/dctcp
- DCTCP-CS244-2013 – https://reproducingnetworkresearch.wordpress.com/2013/03/13/cs244-13-dctcp/
- DCTCP_queue_sizing-CS244-2013 https://reproducingnetworkresearch.wordpress.com/2013/03/13/cs244-13-dctcp-queue-sizing/
- DCTCP-CS244-2012 https://reproducingnetworkresearch.wordpress.com/2012/06/06/dctcp-and-queues/
README
- Launch an instance with our AMI DCTCP_CS244_16 (us-west-2 region) and in Configure Instance Details, please select tenancy as Dedicated – Run a Dedicated Instance. Be sure to allow all TCP, UDP and HTTP traffic from anywhere while setting the security groups.
- Ssh to the instance.
- Clone the dctcp repo – hg clone https://priyaduraisamy@bitbucket.org/priyaduraisamy/dctcp
- cd into dctcp folder
- sudo mn -c && sudo ./run.sh
The experiments totally take about 1 hour to run. Please ensure ssh connectivity does not break while the code is running. Alternatively, you could run it on a separate screen and detach it and check after about an hour.
In the end, there is a folder results within dctcp that contains the results. We observed very rarely that the resulted figures are a bit off from what is expected – we think it is due to load variations on AWS servers. If this happens, we request the reader to run it again to see the results if are ok.
To view the graphs :
- cd /dctcp/results
- python -m SimpleHTTPServer
Open a browser and type <instance_ip>:8000 and open each image to view. The images are named appropriately so you can identify them easily.
Instructions to build the kernel from scratch – for future batches (if our image gets pulled down from AWS) :
- Launch an Ubuntu 12.04 instance with Root volume 12 GB. While selecting security groups, be sure to allow all TCP, all UDP and HTTP traffic from anywhere.
- ssh to the instance
- sudo apt-get update
- sudo apt-get install git
- git clone git://github.com/mininet/mininet
- sudo mininet/util/install.sh -a
- sudo mn –test pingall
- git clone https://github.com/mininet/mininet-tests.git
- Follow instructions from [2] to install the DCTCP patch until (and including)
- Open /boot/grub/menu.lst in an editor of your choice (as root) and add the following lines to invoke this kernel by default. These lines should be added towards the bottom of the file above all existing similar entries. Give a title to identify the kernel. Use root,kernel and initrd same as the others in the file but change what follows vmlinuz- and initrd.img- to 3.2.18-dctcp. Leave the other parameters as it is.
title Ubuntu 12.04.5 LTS, kernel 3.2.18-dctcp
root (hd0)
kernel /boot/vmlinuz-3.2.18-dctcp root=LABEL=cloudimg-rootfs ro console=hvc0
initrd /boot/initrd.img-3.2.18-dctcp
11. Reboot the system using reboot
Ssh back into the system
12. sudo apt-get install mercurial
13. sudo rm -rf /usr/local/bin/mn /usr/local/bin/mnexec \
/usr/local/lib/python*/*/*mininet* \
/usr/local/bin/ovs-* /usr/local/sbin/ovs-*
14. sudo apt-get install mininet/precise-backports
15. sudo service openvswitch-controller stop
16. sudo update-rc.d openvswitch-controller disable
17. sudo mn –test pingall
18. sudo apt-get install python-pip
19. sudo pip install termcolor
20. sudo pip install matplotlib
21. sudo apt-get install bwm-ng
22. hg clone https://priyaduraisamy@bitbucket.org/priyaduraisamy/dctcp
23. Now follow the steps given previously to run the experiment.
The above steps take ~3-4 hours to complete.

Good job! I was able to reproduce the graphs in the blog in about an hour following the instructions. At the beginning of the experiment, the code generated a few errors such as “ERROR: Module tcp_probe does not exist in /proc/modules
Killed”
but the code ran to completion and generated the same graphs as detailed in the blog. I liked the analysis suggesting that the reproducibility of the sawtooth graph could be due to unsynchronized senders, which you mention you cannot do in Mininet. In our project, we encountered similar limitations of Mininet, so it was cool to see your descriptions of those challenges. Overall, it looks detailed and well-written. In terms of the rubric for reproducibility of the graphs, I think a 5 is appropriate, as many of the graphs are similar to the paper, with a few differences as mentioned above with the sawtooth and timescale differences. With the graders’ discretion, they may bump that to a 4 or somewhere in between 4-5.