Authors: Henry Wang, Jacob Haven
Goals and Motivation of the Original Paper:
The paper we chose to study was “Operational Experiences with High-Volume Network Intrusion Detection” published in 2004. The authors of the paper describe experiences using Bro, a popular open-source network intrusion detection system.
It is used on many large scale networks and it is thus very important that it scales well with long term usage. The authors focusing mainly on difficulties arising from resource constraints over several networks running Bro. The practical experience of running a network intrusion detection system is that the resources used grow rapidly with increases in network traffic. This paper tests this intuition by measuring the general behavior of Bro with respect to the size of the logs (directly proportional to the amount of time since Bro has begun to capture data).
Results:
By deploying Bro on their network and measuring its performance over the course of a few days, the authors found that Bro does not scale well over time, tending to exhaust the system’s memory as well as CPU usage until the system crashes.

Original paper results for memory required by scan detector
The authors next tried to optimize behavior by deleting obsolete timers and trading detection-rate for memory usage by dynamically (de)activating protocol decoders. Though this helped Bro’s performance, it significantly limited the effectiveness of Bro as an NIDS at high memory usage levels. More importantly, the problem of linear scaling persisted.
Subset Goals and Motivation:
We chose to focus on user-state memory management discussed in section 4.2 of the paper and reproduce the results from the graph shown above. Here they plot the Bro system’s memory state against the elapsed time since Bro startup. The user script they test against (conn.bro) keeps track of state for each connection seen. The longer Bro runs, the more memory is needed to maintain this state, until it eventually crashes.
The metric of log size versus performance (in terms of memory state) is an important result to analyze, while still being feasible for this project. Measuring the memory usage and capabilities of Bro under different circumstances will give valuable insight on the abilities of Bro in a relevant setting. In addition, this overall behavior can still be generated if we scale down the quantity of the packet logs, allowing us to simulate our own traffic over a more reasonable timespan to measure Bro behavior.
Subset Results:
We conducted our experiment using Mininet over Amazon’s ec2 instance. To simulate traffic, we took advantage of nmap’s ability to scan large numbers of ports very quickly while using only two hosts. The number of ports scanned was slowly dialed up from 0 to 10000 in 500-port intervals. To estimate Bro’s memory usage against this traffic, we took advantage of /usr/bin/time’s ability to report the number of minor page faults and multiplied the output by 4KB. The results of our data can be seen below.

From the graph, it is clear that our results are quite consistent with the findings in the paper: Bro’s memory usage exhibits a very distinct linear relationship with the amount of traffic it must deal with. This data provides good evidence to back up the paper’s claims.
Extensions:
In the data above, we made an important assumption that Bro behaves similarly when dealing with port scans from one host and long-term TCP flows from many hosts (Bro’s memory usage is concentrated in recording flow states, not the hosts or flows themselves). To verify this, we analyze a second data set, where we measure Bro’s memory usage against a variable amount of long-term TCP flows from multiple hosts. To create these TCP flows, we construct a topology of 1 server and 300 clients. We start Bro and server-side iperf on one node while choosing a subset of the client nodes to start iperf connections with the server (a range of 0 to 300 clients in intervals of 50). The results can be seen below.
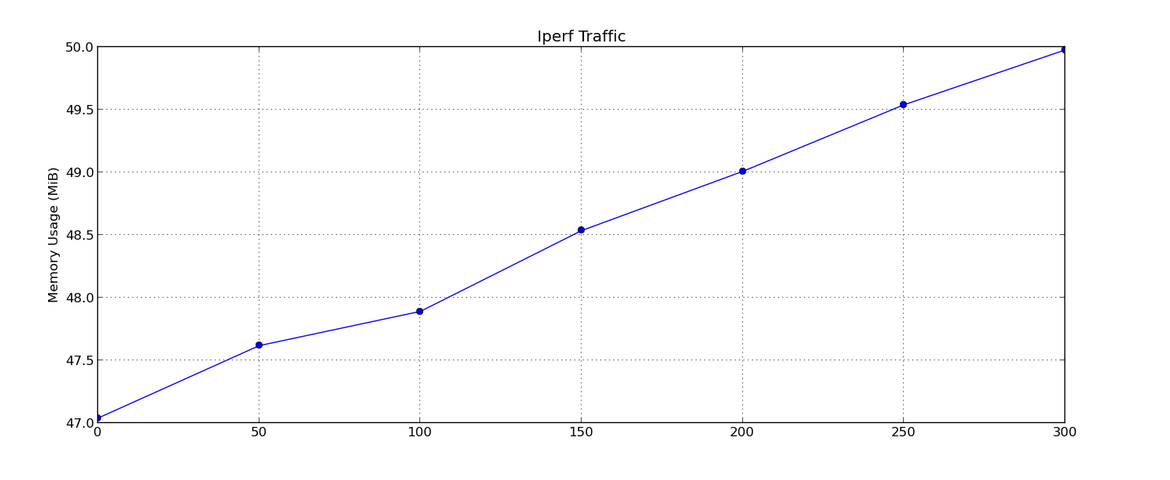
From the above graph, we can be fairly confident that the behavior of Bro with respect to long-term TCP flows is still linear, similar to that of simple port scans. This supports our earlier assumption that Bro focuses on recording and analyzing flow state.
Another area of interest is whether Bro behaves differently with different layer 4 protocols. To test this, we perform a similar study as the long-term TCP flows above, but replacing the iperf commands with ping trains. The results can be seen below.

From the graph above, we can see that Bro’s behavior is once again linear with respect to the number of different client requests, implying that Bro behaves similarly regardless of layer 4 protocols. The fact that all these individual behaviors scale linearly cumulatively supports the paper’s data on the overall memory usage of Bro.
Implementation Challenges:
Luckily, Bro is open-sourced, and the developers have published various methods of downloading the package. Though some setup was required after downloading the source, including configuring, compiling, and setting environment variables, Bro was up and running without too much trouble.
One of the major challenges, however, was obtaining the data required to observe Bro’s behavior. Because we do not have access to central routers, reproducing the paper’s results from live captures was not possible. We initially worked around this by searching for various-sized pcap files from databases on the Internet, resulting in the graph shown to the left.
However, due to the unpredictable behavior of Bro on small pcap files and the lack of larger pcap files on which to test, it’s clear that these results were not enough to make valid conclusions in either direction. We thus decided to simulate live traffic by running a more controlled series of tests with Mininet on the ec2 instance, generating the three graphs shown earlier. Here, the limitations of Mininet became the major challenge, as we observed significant breakdown in performance as the number of hosts in our topology reached ~500. As a result, we decided to use nmap to generate our main result, as it was the most efficient way to force Bro to save an equal amount of state using only two hosts.
Another challenge we faced was getting Bro to run multiple times in the same script in a synchronous manner. As an NIDS, Bro is meant to start up once, perform setup, and capture data for an extended period of time before cleaning up and shutting down. By starting and killing it many times in rapid succession, we often faced synchronization issues (i.e. a second instance began before the first one was able to fully terminate). Running nmap within Bro and running the whole thing within /usr/bin/time compounded the issue, resulting in the necessity for several sleep() calls to ensure proper behavior.
Critique:
The findings in the paper closely match the results we reproduced, a fact from which we can conclude two things. Firstly, the paper’s main thesis and results hold well over the scope of the research (live traffic, as trace data results for us were inconclusive). Secondly, despite active research and improvements to Bro, the linear relationship between the amount of traffic and memory usage has not changed since the paper was written. This supports the paper’s claims that memory usage is a critical bottleneck for Bro usage. In addition, because these tests were done under normal traffic conditions, memory usage can scale even worse under adverse conditions, for which Bro is meant to be used. Though we were unable to produce the sheer amount of traffic necessary to stress-test Bro due to Mininet and ec2 limitations, it is reasonable to assume that, had our tests continued to grow in size, Bro would follow the pattern and crash as the paper claims.
Platform:
As stated above, we chose to use Mininet as a way to simulate a large, steady amount of live traffic as we do not have the means to obtain real live traffic of this scale. By creating a server and controlling the amount of clients and flows that are speaking to it at any one time, we can get an accurate assessment of Bro’s activity that would be unfeasible through trace data or simple ping trains.
README:
#Note that due to the nuances of installing Bro on an ec2 instance, we have
#created a new EBS AMI for launch that comes with Bro, nmap, and all the
#relevant source files needed to run this experiment.
Launch a new instance using the image “cs244-spr14-bro-metric-analysis” on
US-West (we found that a c3.large instance works well enough)
#Start the instance and ssh into it. Inside the ec2 instance, run:
cd bro-metrics-project
./run.sh
#This will automatically run Bro multiple times and analyze its behavior
#against:
# nmap with 0 to 10000 ports in intervals of 500
# iperf with 0 to 300 clients in intervals of 50
# ping with 0 to 300 clients in intervals of 50
#The outputs of the analysis (raw text data and graphs) can be found in the
#output_data directory.
#Note that the slowest parts of this experiment are the nmap analyses with
#large number of ports and the topology setup/teardown of 301 hosts. To run
#this experiment faster, you can increase the interval between nmap tests
#(change range(0,10001,500) to range(0,10001, 1000)) and/or decrease the number
#of nodes (change n=301 to n=101, 151, 201, etc). Note that for the second
#option, you will also have to change the upper bound of the ranges in the
#iperf and ping loops accordingly.

We found the results of this experiment very easy to reproduce, and graphs produced directly matched those in this post. Score: 5.
We liked that you tested scalability under different load types, and that you did try with multiple hosts even though you ran into breakdowns with Mininet at high node counts. It seems like your work is mostly generalizable, but it would be nice to have run some kind of longitudinal study to see the effects on Bro state over time as in the original paper, as opposed to just the number of connections.