Ana Klimovic and Chuan-Zheng Lee
Introduction
Many of today’s large-scale datacenter applications are sensitive to tail latency. A web search request may access on the order of 10,000 index servers, returning only after the slowest sub-request has finished. This means that even if only one in 10,000 requests is slow, it will still severely impact the overall performance of the application.
Network interference is a major source of high tail latency. Datacenters typically host a wide variety of applications with different performance requirements, such as throughput-intensive batch jobs and latency-sensitive services like memcached. When throughput-intensive applications congest the network, queues build up and delay traffic from latency-sensitive applications.
The goal of QJump is to provide a simple and immediately deployable mechanism for controlling network interference in datacenters. By assigning each application to a latency sensitivity level (which is coupled with a rate limit), QJump allows datacenter operators to explicitly and individually control the throughput vs. latency-variability tradeoff according to the performance requirements of each application.
Unlike previous work on QoS technologies such as DiffServ, which struggled for widespread deployment in the Internet, QJump takes advantage of the controlled nature of the datacenter environment where operators can enforce system-wide policies to provide latency guarantees.
How QJump works
For the most latency-sensitive applications, QJump bounds worst-case latency by prohibiting hosts from sending more than one packet per network epoch. The network epoch is set so that no packet can experience a delay greater than that which would be caused by contention from one packet from every other host in the network. Latency-sensitive applications are given strict priority: their packets “jump” over all other packets queued at a network switch. The implication of rate-limiting is that latency-sensitive applications must sacrifice throughput in order to gain priority (and low tail latency).
Throughput-intensive, latency-indifferent applications are neither subject to such rate-limiting nor given latency guarantees. Applications in between on the latency-throughput trade-off are similarly rate-limited, but their network epoch is reduced by a throughput factor. A shorter network epoch relaxes the rate limit, but introduces more potential for contention (and hence larger tail latency). Applications with lower throughput factors always jump the queue over applications with higher throughput factors.
The authors implement QJump as a Linux traffic control (TC) module, which uses 802.1Q tagging to specify the priorities of the various streams.
Results of authors
The authors demonstrated with a range of tests that QJump substantially mitigates network interference and improves response times for latency-sensitive applications compared to other deployable congestion control schemes. Using ping and Iperf, they found a reduction in median switch latency for ping packets from about 900µs to 3µs when QJump was enabled; with memcached and Hadoop, median memcached request latency dropped from about 800µs to 500µs. They also simulated QJump on ns2 with typical datacenter workloads, showing that 99th-percentile flow completion time drops by a factor of 5 relative to Data Center TCP.
Results reproduced
We reproduced a modified version of Figure 3a. In this figure, the authors show a cumulative distribution function of switch latency for ping packets, with and without an interfering Iperf stream, with and without QJump. We chose this figure because it cleanly demonstrates the basic effect of QJump, and because ping and Iperf can be run in a Mininet environment.
The authors ran this test in hardware using Arista switches with 10 Gb/s links, and measuring switch latency using an Endace data capture card. Naturally, neither of these are emulatable in Mininet. We therefore modify our experiment in two ways:
- We measured ping round-trip latency, as reported by ping, rather than switch latency.
- We emulated much slower links: we ran our experiments at 10 Mb/s. We have script options to try higher and lower link rates to see the effect.
We therefore recomputed QJump configuration parameters for our particular setup, rather than using the exact parameters the authors used for their figure with their hardware setup. This was straightforward since the paper explains the formulas in detail.
timeq = network_epoch =


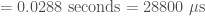
where 


We used the same topology as the authors show in Figure 4 of the paper, but we only ran one Iperf stream, from host H7 to host H10. We ran ping from host H8 to host H10.
In their NSDI ’15 paper, the authors used a broken x-axis scale to plot the cumulative distribution function. We provide two plots, one of the entire figure, and one excluding the “ping+Iperf without QJump plot” to allow us to zoom in on the other two:


The plot without QJump (the red line) show a uniform distribution of latency. This is a reflection of Iperf’s TCP stream’s congestion window building up over time. The above results are for 30 seconds, short of when (in our setup) TCP hits its maximum congestion window. When the test is run for longer, the maximum latency increases with the growing congestion window (and the distribution is then uniform over a larger range).
Challenges during result reproduction process
We encountered several implementation challenges, of which we list a few:
Invariant timestamp counters not supported on virtual machines. The traffic control (TC) module checks that the machine’s processor supports an invariant timestamp counter (TSC), and refuses to install if it does not. Virtual machines, however, do not support invariant TSC, and Mininet runs on a virtual machine.
Resolution. We consulted the authors, who advised us that some simple code modifications could work around this. QJump would then use the kernel clock rather than the TSC to judge timing, with some consequential loss of accuracy.
Traffic control module conflict. Mininet also uses TC modules to limit its bandwidths. Thus, the command to install QJump as a root module does not work.
Resolution. We installed QJump as a child TC module of Mininet’s TC module for link bandwidth limiting.
VLAN setup. QJump relies on 802.1Q priority tagging, which requires that VLANs be configured on all hosts. The authors give instructions for the correct configuration of VLANs, which we found to be insufficient. We found we also needed to configure hosts so that they would send over the VLAN interfaces (instead of the physical interfaces) using the ifconfig utility.
Resolution. To achieve this, we used the VLANHost class in the Mininet examples directory. This meant our scripts did not need to add the VLAN port; they only needed to configure priority mappings as the authors describe.
Support for multiple queues in hosts. Mininet creates virtual network interfaces with only one transmit queue, which means that QJump cannot use multiple queues to prioritize packets.
Workaround. We added numtxqueues 8 to the ip link add command in (a fork of) the Mininet code. For now, this is hard-coded. Eventually, we hope that it would be made an option to Mininet.
Support for QoS in the switch. In addition to multi-queued NICs at host machines, QJump requires switches with multi-queued interfaces. The default OVS switch in Mininet which we were originally using did not support multi-queued switch interfaces.
Resolution: We used the OVSHtbQosSwtich in Mininet in order to support multiple queues at the switch interfaces and allow for prioritization.
Discussion
It is worth acknowledging that Figure 3a only evaluates part of QJump’s contribution. Our ping traffic never gets rate-limited, so the only net effect of QJump is to prioritize it over the iperf traffic, in effect verifying QJump’s TC module implementation. Our work shows that QJump’s promise holds in this most basic case.
Quantitative matches will clearly be infeasible: Mininet’s emulated links are nowhere near 10 Gb/s. But the qualitative nature of our figures matches those of the authors. Specifically, we confirm that running ping and iperf together induces the famous bufferbloat effect, and that using QJump reduces ping latency almost to what it is when ping is run on an idle network. Like the authors, we found that not all of the additional latency caused by iperf was eliminated when we enabled QJump, but it got very close. The basic result holds despite the fact that we measured round-trip latency rather than switch latency.
We could test the rate-limiting part of QJump by setting the timeq parameter to be much longer than the ping interval, and verifying that fewer pings are sent (as QJump limits ping). We tried this as a sanity check and found this to be the case, but did not quantify the effect.
Instructions to reproduce
Instructions to run our experiment are on in our GitHub repository.
Acknowledgements
We wish to acknowledge the authors of the NSDI ’15 QJump paper, in particular Matthew Grosvenor and Malte Schwarzkopf, who were very helpful in answering our many questions about their work.

{kind=link}
5/5: Setup was quick and clearly explained! The experiment itself ran smoothly and produced the same results as predicted. We were impressed by the challenges you faced along the way and how you were able to resolve all of them.
Pingback: CS244 ’16: Reproducing QJump Results | Reproducing Network Research·
Pingback: CS244 ’16: QJUMP – Controlling Network Interference | Reproducing Network Research·