Team: Anna Saplitski (annasaps@stanford.edu), Truman Cranor (trumanc@stanford.edu)
Key Results: QUIC’s loss recovery mechanisms allow it to get higher throughput than TCP at high loss rates, but it’s unclear if QUIC gets higher throughput in low-loss environments.
Sources: QUIC Loss Recovery RFC, Google presentation on QUIC
Introduction
HTTP[S] and TCP are, respectively, the most popular application and transport layer protocols on the Internet (and it isn’t even close), but there are well known issues with the combination of protocols. One issue is that TCP is implemented in the networking stack of user machines, so improvements require updating the kernel of your OS, slowing their adoption. Perhaps a larger issue is the inherent mismatch between the needs of the HTTP[S] application layer protocol and the TCP layer’s guarantees. A classic example of this is when an HTTP[S] connection attempts to multiplex the download of several resources over a single TCP connection. Because TCP guarantees a single, reliable, in-order byte-stream, a lost packet that should have only affected one resource’s download now causes head-of-line blocking and delays delivery of the bytes from the other logically distinct HTTP[S] streams to the handler because it would violate TCP’s in-order guarantee.
As a response to these and other issues with TCP, Google has introduced the Quick UDP Internet Connection protocol (QUIC), which aims to separate TCP-like functionality from the slow-changing kernel-space network stack, and instead implement it as a user-level transport layer built upon UDP. By implementing this functionality at a user-space level, QUIC is able to quickly deploy new loss-recovery mechanisms without kernel updates, and can relax requirement that TCP imposes on application protocols like HTTP[S].
Motivation
QUIC has quietly been shipped to half of the Chrome browsers online today, and is being used for an increasing percentage of traffic between Chrome and Google servers, so it accounts for a significant (and growing) fraction of Internet traffic. The fact that it is so little-studied compared to TCP means there’s a large gap in our understanding of how Internet traffic behaves. While we wait for the QUIC team to publish an official paper about their protocol, we can investigate various aspects of the QUIC protocol’s improvements over TCP.
QUIC
QUIC doesn’t yet have an official publication, so our analysis of the following claims and our attempts to reproduce them should be taken with a grain of salt; some claims may have applied to previous versions of the protocol and implementation.
In a presentation linked on the QUIC homepage, the QUIC team makes several claims about the performance of QUIC, and how its numerous features shorten download times. QUIC includes new features like 0-RTT connections, pluggable congestion control, forward error correction, and multiplexing without head-of-line blocking. The claim we are most interested in testing is QUIC’s loss recovery mechanism: this same presentation claims that QUIC can make reasonable progress even at 50% retransmission rates.
QUIC’s loss recovery mechanisms include features like tail loss probes and fast retransmit, which attempt to detect packet loss efficiently without having to wait for a traditional RTT based timeout. Arguably the most important change is the addition of fields that allow for more intelligent and unambiguous ACKing of data. QUIC acknowledgements includes 256 NACK ranges, which allows a receiver to describe more accurately which packets have been received and which have not; this is an improvement over regular TCP which simply ACKs the next byte number that hasn’t been received with no information about the bytes beyond that number. In addition, the protocol separates the sequence number from the packet number, which is unique and monotonically increasing for each packet (including retransmissions) that is sent. This feature eliminates many edge cases in TCP algorithms that can’t tell if an ACKed packet is the original packet or a retransmission. The QUIC team claims that the accumulation of these improvements means that QUIC outperforms TCP in lossy environments.
Subset Goal
We’ve attempted to replicate the result that QUIC performs better under highly lossy environments. We run Google’s provided QUIC client and server implementations in an emulated lossy environment and compare download times with standard TCP downloads in that same environment.
Our emphasis on the loss-recovery mechanism is spurred by the increasingly popular wireless networks, including mobile provider networks and WiFi, and the understanding that these wireless networks typically exhibit higher loss rates since transmission success depends on radio transmitters instead of just buffer queues.
Platform
We wanted to isolate the loss recovery mechanisms as much as possible, so we decided to use a single link for our experiment set-up. Since we only need to control the characteristics of the one link, our tests can be run in a Mahimahi emulation. Mahimahi was also a good choice because we wanted a lightweight tool that we could configure from the command line.

The real world set-up we want to emulate

Our Mahimahi testbed
We chose to run the client inside Mahimahi rather than the server because the servers have much longer set-up times. We’d prefer not to respawn the servers for every single test, each of which require a new Mahimahi shell.
We use a chain of 3 nested Mahimahi shells to achieve the desired effect:
- Force downlink packets (data downloaded from the servers) to be lost at several different rates between 0-15% (uplink packets, i.e. syns and acks do not get lost).
- Limit the rate of packets to some definable threshold (this is necessary to ensure the tests we run are correctly measuring the protocol’s loss-reaction and not bounding the computation by CPU) between 1-100Mbps.
- Add a small delay between 1-10ms to simulate a reasonable real-world RTT.
Experiment
To retrieve the data over QUIC and TCP, we used Google’s toy QUIC server/client implementations and the wget utility. We chose to use wget rather than a throughput-measuring utility like iperf primarily because it emulates the full HTTPS/TCP stack.
For each flow, we retrieved a single 12MB webpage and compared throughput by measuring the page download times of the QUIC client v. wget. To measure page download times, we used the Unix time utility, which we confirmed gave very close results to wget’s self-reported throughput. We chose a large file to ensure that the effects of other mechanisms in QUIC had a minimal effect on completion time. In particular, QUIC has 0-RTT connection set-up and TCP requires at least the three-way handshake, so short flows can’t necessarily isolate loss recovery mechanisms. We only downloaded a single resource because we didn’t want any of the difference to be attributed to QUIC’s multiplexing without head-of-line blocking. Finally, to ensure that any differences between the protocols are caused by loss recovery only, we make sure to use the same congestion control algorithm (TCP Cubic) for both protocols.
To make this set-up easier in the future, we created a linux VM with Chromium, Mahimahi, and other utilities installed. See the Reproducibility section for how to run this experiment on your own machine.
Results
In short: QUIC really does get better throughput in highly lossy environments, but it’s not clear if it performs better than TCP in lossless or low-loss environments.
Both protocols see degradation as loss rates increase, but the slope of TCP’s degradation is much steeper. Even when this QUIC implementation is CPU-bound, it outperforms TCP consistently at high loss rates. Depending on how CPU-bound the QUIC implementation is, it can overtake TCP anywhere between 1-5% loss rates. See the Challenges section to see how this QUIC implementation impacted the results.
Both protocols see higher throughput with higher bandwidths and lower delays. Below is a representative picture when QUIC is not CPU-bound.
Challenges:
Configuring this experiment took a substantial amount of time. QUIC isn’t available in a standalone implementation, so we had to download the full Chromium source code and compile the relevant binaries (quic_server and quic_client).
Because we were experimenting on encrypted traffic, we had to a lot of extra haggling to get the servers and clients to communicate correctly. The QUIC documentation isn’t totally clear on how to set up certificates correctly (which requires configuring a new root certificate database on the machine). We also had to set up our own HTTPS server, which was non-trivial. With Mahimahi’s IP address modifications in the mix, there was a lot of testing to make sure that this worked correctly.
Critique
The biggest issue we came up against was that the QUIC implementation was aggressively CPU-bound for pretty low delays (10ms) or bandwidths (20Mbps). This wasn’t unexpected, since the documentation warns that this implementation is not performant at scale, and is meant primarily for integration testing. This meant that QUIC simply couldn’t keep up with TCP at higher delays or bandwidths with low loss rates, although QUIC still consistently overtook TCP at high loss rates.
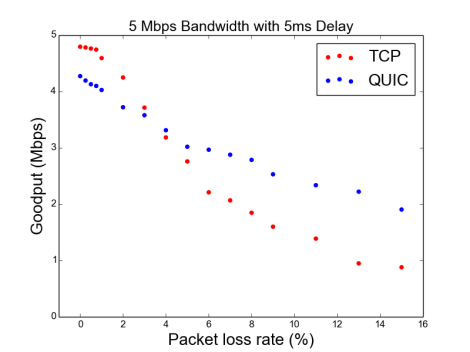
Below is a graph that shows how aggressively this QUIC implementation is CPU-bound. As you can see below, at a mere 5ms delay, QUIC tops out at 4Mpbs, as in the figure in the Results section, even when the available bandwidth is 20Mbps and 100Mbps:



Furthermore, this QUIC implementation degrades aggressively in the face of delay. While TCP also sees a degradation in throughput with higher delays, QUIC’s performance degradation is much higher. Looking across bandwidths, we see QUIC top out at 10Mbps for a 1ms delay, 4Mbps for a 5ms delay, and 2.5Mbps for 10ms delay.


It’s worth noting that, despite its CPU-boundedness, QUIC still outperforms TCP at high loss rates. We expect that with a better implementation of QUIC, we’ll see even bigger gains over TCP. What we could not assess was how well QUIC performed relative TCP in lossless or very low-loss environments. Our initial observations suggest that QUIC should be comparable, but we were only able to confirm this at low bandwidths (1,5,10Mbps).
We confirmed with manual testing that this CPU-bounding problem was a symptom of that particular client, and not inherent to the protocol. We manually tested throughput using the Chromium browser, which has the QUIC protocol turned on by default. Chromium’s QUIC implementation showed none of the same performance issues and may even outperform TCP. Ideally, we would have liked to use Chromium to perform the downloads and run these tests since it performed much better, but we ran into insurmountable problems when trying to tests through Chrome on the command line: Some issues included:
- We couldn’t figure out how to detect automatically that a page had loaded.
- We couldn’t figure out how to automatically collect stats about page load times, though there exist GUI elements to detect this.
- Because of (1), we didn’t know when to kill chrome windows, since they don’t close automatically.
- Finally, Chrome automatically caches web pages, a feature which can only be disabled in the GUI when the developer console is open.
In short, the major issue with claims about QUIC is that at this early stage, we don’t have mature implementations to test. Our ability to actually run QUIC is limited to the tools that Google provides, and the raw command line client, while accessible, wasn’t performant enough for everything we hoped to test. Hopefully, when the QUIC team finishes its paper, it’ll offer an implementation of QUIC that is optimized and lightweight enough for the desired reproducibility.
Reproducibility
To reproduce the results, follow these steps:
- Download: the pre-configured VM here. (Note: it’s 11 Gb, so plan accordingly.)
- Import: the VM into VirtualBox by “Importing Appliance”; this can take 15-30m.
- Install: run ~/configure.sh script, which clones the relevant git repository.
- Run: run ~/CS244-16-Reproducing-QUIC/experiment_scripts/run_test.sh. Note that at the beginning of the script, you’ll need to authenticate as sudo to allow Mahimahi to run.*
- Examine: all the relevant graphs will be in ~/CS244-16-Reproducing-QUIC/graphs/.**
*If you want to just generate the graphs from the blog post, you can just run the script directly. If you’d like to run the entire experiment, open the run_test file and uncomment the lines as directed. Be warned that this takes ~12 hours!
**If you’d like to compare against the full set of graphs we generated, check ~/CS244-16-Reproducing-QUIC/previously_generated_graphs/.
Note that the graphs show points at which the quic client is cpu-bound, so running these tests on different machines will show different results and thresholds in those tests. For tests that aren’t CPU bound (i.e., those with low bandwidth and delay parameters) we expect the graphs to be entirely reproducible.

This blog post is very well written and draws some decisive conclusions about QUIC under certain conditions.
Reproducing Anna and Truman’s results was extremely easy. After downloading the VM, running the tests was just one shell script! We observed the same results as shown in the blog, albeit with slight fluctuations in the exact timings. The trends seen in both were identical. 5/5