1. Goals
It is often the case that there are multiple physical paths between two hosts. TCP is not designed to take advantage of this redundancy. Flows that have been started on a slow link, for example a 3G connection, cannot take advantage of other faster interfaces on the same host. Multipath TCP (MPTCP) attempts to resolve this issue. A connection running MPTCP can migrate to a discovered stronger link to improve the overall performance. Additionally, the authors of the MPTCP paper[1] wanted to implement MPTCP in a way such that it is instantly deployable on the internet today. This goal creates challenges such as coping with middleboxes rewriting TCP options, sequence numbers and modifying the packet in general.
2. Motivation
It is commonly known that redundancy improves availability. The additional redundancy provided by MPTCP allows devices that may have poor links, such as a mobile phone, to handle link performance fluctuation and failure seamlessly from the application’s perspective. MPTCP allows a connection to be handed off from a 3G link to a Wi-Fi link such that the application continues to function normally. Furthermore, if a link’s performance degrades, MPTCP can switch over to a different link with better performance.
3. Results
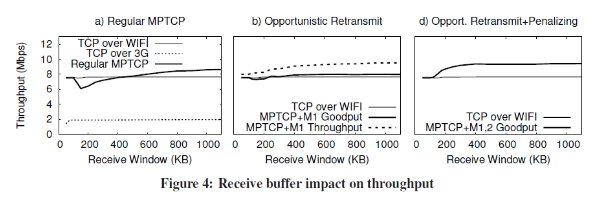
In theory, MPTCP should be easy to deploy, the workarounds required to deal with middleboxes that rewrite packets make up the majority of the paper. Moreover, some TCP parameters, such as receive window size, can greatly affect performance if MPTCP does not account for effects of multiple links sharing a receive window. In the paper, the authors examined the impact of receive buffer size on MPTCP, considering a setup that allowed MPTCP to simultaneously take advantage of both WiFi and 3G connections (page 12). In their test, the authors determined that with a sufficiently large buffer, MPTCP is able to utilize both the WiFi and 3G connections. With a 100KB buffer, MPTCP achieves a goodput 25% higher than regular TCP over WiFi or 3G. Furthermore, with a 200KB buffer, MPTCP “gets most of the available bandwidth” along both links, while with a 500KB buffer, MPTCP achieves nearly double the goodput of regular TCP.
4. Subset Goal
We decided to reproduce the results captured in Figure 4 of the paper. These results demonstrate the impact of receive window size and specific MPTCP optimizations (opportunistic retransmit and penalizing) on overall throughput and goodput. As the name suggests, opportunistic retransmit allows faster subflows to retransmit data that is holding up the receive buffer. It is termed opportunistic since the faster subflow would otherwise be idle, waiting for the slower subflow to catch up and move the receive window forward. The penalizing slow subflow optimization cuts down the receive window of an observed slower subflow in order to allow the faster subflow to transmit more per receive window, hopefully allowing the two subflows to complete transmission of a receive window at the same time, so that the receive window may move forward.
5. Subset Motivation
We chose to reproduce this subset of results because it has a significant and direct impact on the practicality of deploying MPTCP in the current Internet. First, the results are important because they demonstrate that MPTCP can be implemented to perform no worse than ordinary TCP. In other words, these results establish TCP’s performance as a lower-bound for MPTCP’s performance. This result is key to the viability of MPTCP – if there were scenarios where MPTCP is unable to match TCP’s throughput, there would be little incentive to actually make the switch to MPTCP. Second, the results show that MPTCP’s receive window can be small. Large receive windows would not make MPTCP viable for deployment on mobile devices where memory is scarce.
6. Subset Results
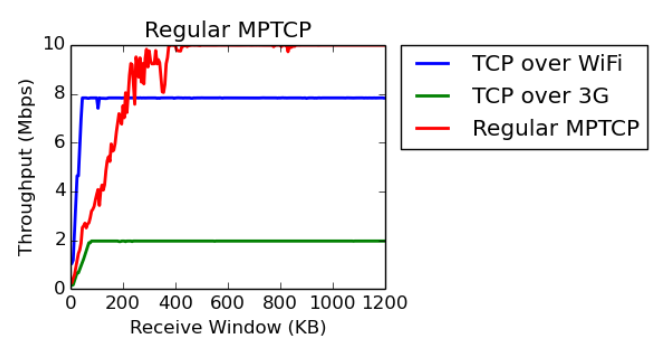
The MPTCP paper specifies the following topology and results. The experiment was run with one sender and one receiver, with two paths connecting the two hosts. One a 3G link with throughput of 2 Mbps and RTT of 150ms, the other a Wifi link with throughput 8 Mbps and RTT 20 ms. The paper then produced the following results for the throughput of MPTCP vs TCP over varying receive window sizes.
In our attempt to reproduce the results, we created a topology on Mininet consisting of the following: two hosts, a sender, a receiver, and two switches connecting the two hosts. The links connecting the two hosts have the specifications given above. Then we began an iperf server on the receiver and an iperf client on the sender. We then sampled the sender’s two interfaces for 1 second three times, taking the median of three such measurements as the measured throughput.
|
Figure a) |

Figure b) |
|
Figure c) |

We created the results at a much finer granularity, measuring the throughput at every increase of 5KB in window size, which produce the jagged nature of our graphs. Although the general shape of our graphs matches the ones in the paper, there are many discrepancies of note. First, we suspect that the original paper did not run the experiments with receive windows smaller than approximately 50Kb, as shown in their graphs. The reasoning is that even regular TCP does not perform well under these tiny receive windows. The paper does mention this, but we wanted to experimentally make sure that TCP does in fact perform poorly under these restrictive conditions. Additionally, TCP’s congestion window sawtooth is a major source of noise, dropping the throughput of subflows as their congestion window is halved due to packet timeouts. We mitigated the effects of TCP’s sawtooth by setting the buffer sizes on the links to the bandwidth-delay product (RTTxC).
Furthermore, we observe that MPTCP appears to do very well even without the optimizations enabled. We are unsure why this is the case, given that the optimizations were designed to eliminate the performance barrier the authors encountered in figure 4a. One possibility might be that we used a more recent MPTCP kernel implementation that has additional unanticipated optimizations. One encouraging result is that the optimizations do seem to allow MPTCP to achieve its highest throughput with smaller window sizes (e.g. 300KB in figure 4b vs. 400KB in figure 4a).
7. Challenges
Over the course of this project, our biggest challenge were setting up the testing environment and running the experiments.These two processes were extremely time consuming. As a result, this fundamentally limited the pace with which we could develop and debug our implementation. Each kernel build took around 4-5 hours, while our experimental runs took anywhere from 6 to over 20 hours.
The time consuming aspect was compounded when we encountered a second challenge involving unanticipated noise in measurements. In attempts to mitigate noisy measurements, we were forced to adopt even more time-consuming methods such as waiting for longer time periods to ensure flows stabilized, and taking the median of multiple measurements instead of being able to just take a single measurement.
Configuring the kernel correctly was also quite difficult given the amount of time that has elapsed since the paper’s publication and the somewhat esoteric EC2 configuration rules that must be obeyed for the kernel to boot correctly. EC2’s custom kernel build requirements combined with long kernel build times made for lengthy test/debug cycles.
Additionally, MPTCP’s documentation on its path manager is lacking. MPTCP’s path manager allows the server to broadcast to clients that it has multiple interfaces, allowing the clients to connect to a different IP address in hopes of finding another path. However, since MPTCP is primarily documented as a client kernel update, this server sided option was difficult to find out.
One more obstacle we encountered was the paper’s lack of detail when describing the queue sizes used along the WiFi and 3G links. On page 8, the paper simply states that the WiFi link has 80ms buffer, while the 3G link has 2s buffer. Because the buffers were specified in terms of time instead of bits or bytes, we ultimately decided (after discussion with our advisor) to assume that the authors had used 1500 byte packets. It would have been helpful if the authors had offered greater insight into the queue specifications (for instance, what size packets were used, or why the buffers were so large), especially since queue sizing has direct impacts on overall throughput.
8. Critique
Fundamental Problems
The problem of slow links blocking a faster link’s receive window is fundamental to any multipath algorithm and isn’t specific to this implementation in MPTCP. Since MPTCP does not immediately know the speed of the paths it is using, it cannot provide the right resources for each path. For example, if MPTCP were to know that a particular path is twice as fast as another, then it would provision ⅓ of the receive window for the slow path and ⅔ of the window for the fast path. Unfortunately, the path characteristics can change over time as other flows enter or leave a bottleneck link, therefore even if relative path speeds are known, a small receive window would heavily cripple MPTCP’s performance when path characteristics change. We undertook this research project in order to explore MPTCP’s capability to cope with these challenges. We found that ‘opportunistic retransmission’ optimization mitigates the loss of efficiency when a slow link holds back a fast link by allowing the fast link to retransmit data that would move the receive window forward. The ‘penalizing slow subflows’ optimization is the way MPTCP dynamically gauges the speed of links, provisioning less resources, which in this case is receive window size, for paths that it deems slow.
Moreover, adding more paths in an MPTCP connection without optimizations will only compound the problem. The slowest subflow will become a bottleneck and degrade the performance of other faster flows. In our experiments for the unoptimized case, we can see that the 3G link holds back the Wifi link by blocking the receive window. By adding more paths, the slowest path will only serve to hold back other faster paths, decreasing overall efficiency.
Loss Rate Sensitivity
In setting up the experiment, we noted that the initial topology setup had all the link loss rates set to 0. We believe this is an unrealistic expectation since Wifi and 3G both suffer from significant losses compared. We hypothesized that as we increased the loss rate on a particular link, MPTCP would treat that link as having less capacity eventually shifting all traffic from the lossy link to a more reliable link. Therefore in gauging the overall goodput available to MPTCP, one must take into consideration the loss rates on each path. We set up an experiment where we varied the loss rate on the faster Wifi link from the same topology as our initial experiment.

From the graph, we could see that MPTCP performs well even when traversing lossy paths. Due to the ‘penalizing slow subflows’ optimization, MPTCP treats the lossy Wifi path as having low bandwidth, thus shifting all traffic to the 3G link as the loss rate becomes significant.
RTT Sensitivity
The receive buffer optimizations implemented in MPTCP has an implicit assumption that the larger bandwidth link can propagate a “receive buffer full” signal faster than the low bandwidth link. To give an example from the initial experiment topology, the opportunistic retransmit optimization assumes that the receiver is able to notify the sender about the Wifi link being blocked by the receive window size and ask for a retransmission of data that would otherwise be sent over the 3G link. Long fat pipes break this assumption. Paths that have high bandwidth and high latency will not be able to notify the sender about being blocked on the receive window size in a timely manner. By the time the sender receives the notification that a long fat path is blocked on the receive window, the lower bandwidth path may have already completely transmitted the data it must send in the current receive window, making the notification useless. We set up an experiment where we varied the RTT of the Wifi link from the original topology and measured the overall throughput.

The results indicated that MPTCP does not react well to long fat pipes, as evidenced by the gap between the MPTCP and Aggregate TCP lines. As hypothesized, as the RTT on the Wifi path increases, MPTCP increasingly begins to treat the Wifi path as a bottleneck. The ‘penalizing slow subflows’ optimization is unnecessarily penalizing the Wifi subflow since it observes that the 3G subflow is able to completely transmit its share of the receive window before the Wifi path is able to respond. The gap between the MPTCP and Aggregate TCP lines decreases once RTT increases to a certain level, because packet drops due to insufficient queueing more severely limits throughput along the WiFi link as RTT increases, which provides greater impetus for MPTCP to avoid using the WiFi link altogether. To achieve optimal throughput, the receive window size must grow with the RTT of the fastest path, a problematic requirement as long fat pipes tend to have large RTTs.
9. Platform
We chose to run the experiment on Amazon’s EC2 platform, using Mininet as our network simulator. The platform and tools we decided to use proved to be extremely flexible. We found that Amazon’s EC2 platform is an extremely versatile platform for our research. In particular, we were able to select machines with specifications we desired. More importantly, the machine specification is easily replicated by any researcher who wishes to reproduce our results. Furthermore, the platform also allowed us to take filesystem snapshots and store them into ‘AMI’s – Amazon Machine Images. AMIs are a virtual machine image that is publicly available for anyone to use, furthering the reproducibility of our results. Mininet is a powerful network research tool that allows us to specify a virtual network topology, starting flows as if they were on real machines. In our experiments, we used Mininet to create a topology with predictable and reproducible results. We found that EC2 and Mininet are very powerful tools for networking research – allowing us to create predictable results that others have easy access to.
10. Reproduction Instructions
Step 1: Launch a c3.large instance using the AMI ami-994033a9
Step 2: git clone https://Laza@bitbucket.org/Laza/cs244-mptcp.git
Step 3: sudo ./run.sh (We recommend running the experiments within a utility like Screen since it can take ~10 hours for all experiments to complete)
Step 4: The output .png files contain the various graphs
Reference
[1] Raiciu, Costin, et al. “How hard can it be? designing and implementing a deployable multipath TCP.” USENIX NSDI. 2012.

We (me and Khaled) reproduced your results using the instructions you provided. No problems, and the results match perfectly (http://1drv.ms/1k1OrPl). 5/5
We also think that the sensitivity analysis performed was pertinent and sensible. Assuming 0 loss on wireless links is indeed unrealistic, and we’re glad you caught that assumption.